大模型比拼:MiniMax M2 vs GLM 4.6 vs Claude Sonnet 4.5
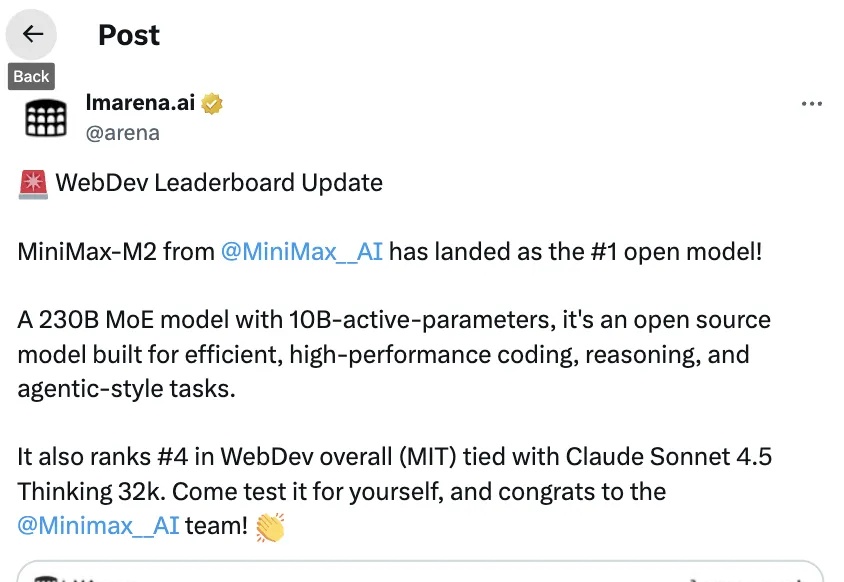
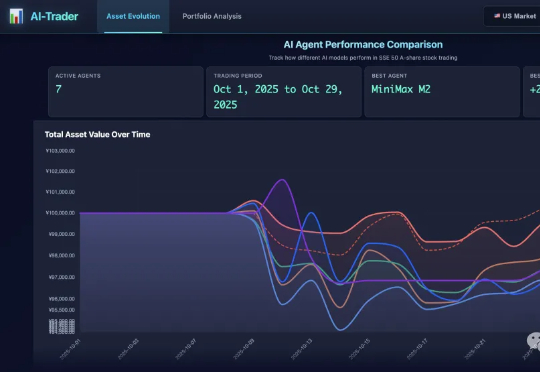
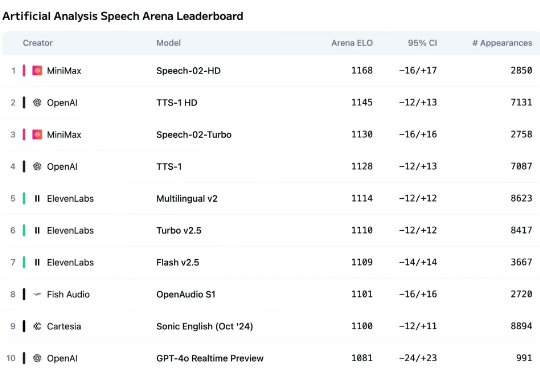
大模型比拼:MiniMax M2 vs GLM 4.6 vs Claude Sonnet 4.5正好上周(10月27日),MiniMax 公司发布了[2] M2 模型,代表了国产大模型的最新水平。我就想,可以测测它的实战效果,跟智谱公司的 GLM 4.6 和 Anthropic 公司的 Claude Sonnet 4.5 对比一下。毕竟它们都属于目前最先进的编程大模型,跟我们开发者切身相关。
来自主题: AI产品测评
10006 点击 2025-11-07 15:32